GNOMEデスクトップトラブル [CentOS]
GNOMEデスクトップが真っ暗な画面のまま起動できなくなってしまいました。
原因は現象が起こる前にパッケージの整理をしていたので、必要なファイルを誤って消してしまったものと・・・
その時の復旧手順を残します。
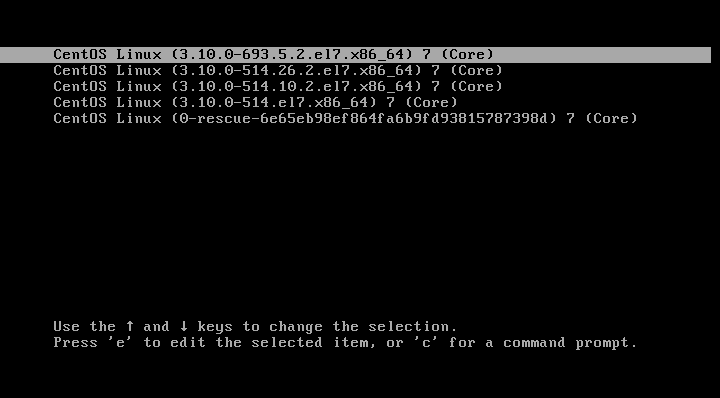
1.ブート画面で'E'キーを押す。
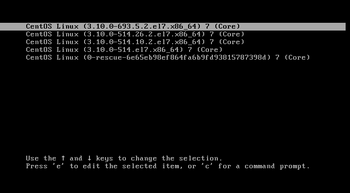
2.起動パラメーターを編集する
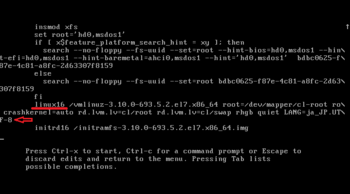
↑"linux16"から始まる項目を探し、末尾にレスキュー設定を追記する。
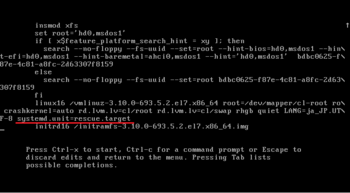
↑"systemd.unit=rescue.target"を追記。
[Ctrl]+'X'キーを押して起動。
3.レスキュー?(Emergency mode)起動
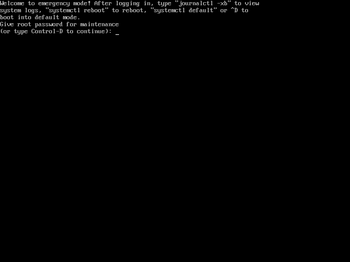
rootパスワードを入力しログイン。
4.ネットワークを有効にする
起動時はネットワークが無効になっているので、有効化する。
# systemctl start NetworkManager
5."GNOME Desktop"を再インストール
まず、"GNOME Desktop"をアンインストール
# yum groupremove "GNOME Desktop"
処理が完了したら、再起動し再度1~4の手順でインストール準備
# shutdown -r now
(再起動せずにインストールしたら、エラーでました)
続いて、"GNOME Desktop"をインストール
# yum groupinstall "GNOME Desktop"
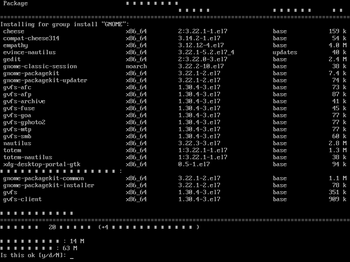
(何だか文字化けしてるけど、気にしない![[あせあせ(飛び散る汗)]](https://blog.ss-blog.jp/_images_e/162.gif) )
)
再起動して、通常起動
6.無事GNOME Desktop復活
無事に復活![[exclamation×2]](https://blog.ss-blog.jp/_images_e/160.gif)
原因は現象が起こる前にパッケージの整理をしていたので、必要なファイルを誤って消してしまったものと・・・
その時の復旧手順を残します。
1.ブート画面で'E'キーを押す。
2.起動パラメーターを編集する
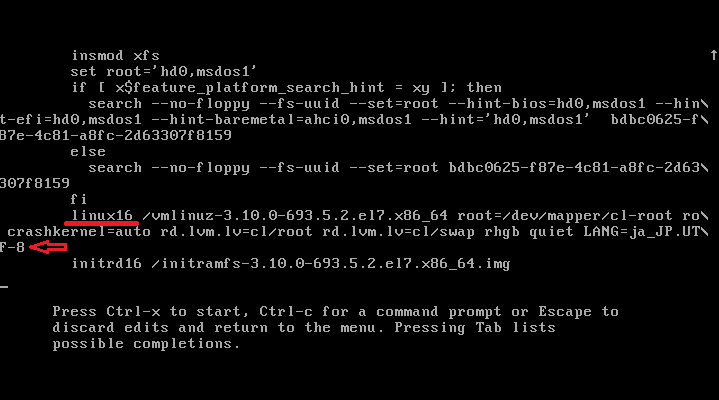
↑"linux16"から始まる項目を探し、末尾にレスキュー設定を追記する。
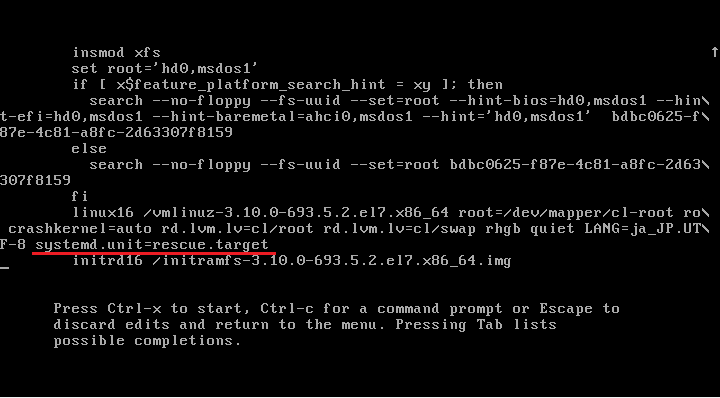
↑"systemd.unit=rescue.target"を追記。
[Ctrl]+'X'キーを押して起動。
3.レスキュー?(Emergency mode)起動
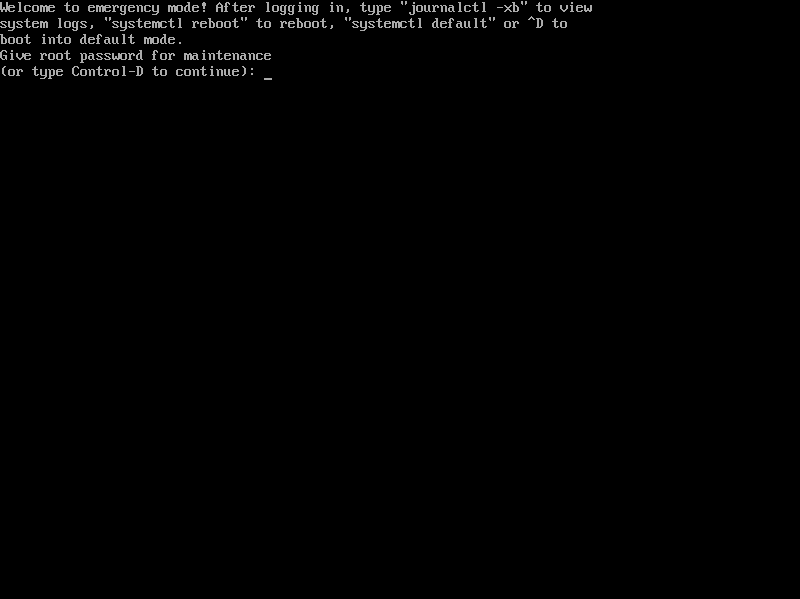
rootパスワードを入力しログイン。
4.ネットワークを有効にする
起動時はネットワークが無効になっているので、有効化する。
# systemctl start NetworkManager
5."GNOME Desktop"を再インストール
まず、"GNOME Desktop"をアンインストール
# yum groupremove "GNOME Desktop"
処理が完了したら、再起動し再度1~4の手順でインストール準備
# shutdown -r now
(再起動せずにインストールしたら、エラーでました)
続いて、"GNOME Desktop"をインストール
# yum groupinstall "GNOME Desktop"
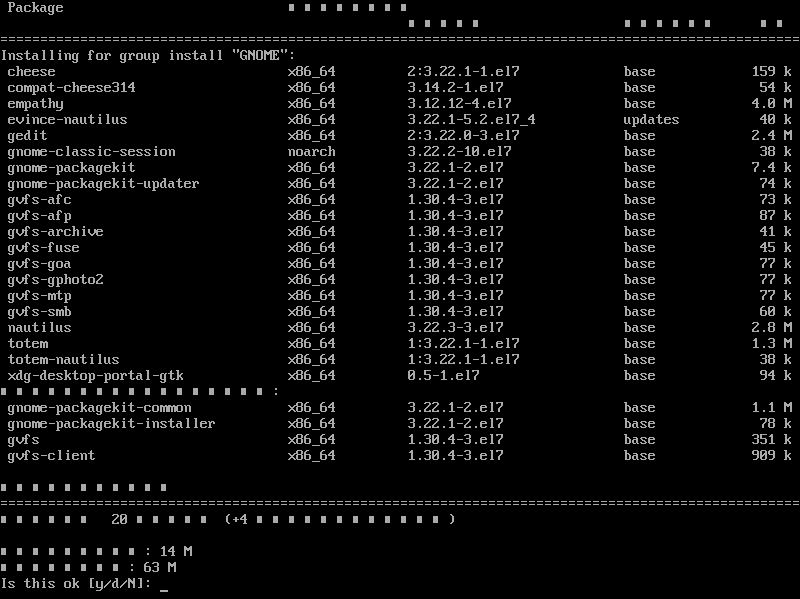
(何だか文字化けしてるけど、気にしない
再起動して、通常起動
6.無事GNOME Desktop復活
無事に復活
ソフトウェアRAIDの管理 [サーバ]
以前ソフトウェアRAIDをGUI操作で構築する手順を書きましたが、
状態の確認や再構築の方法等を考えるとCUI操作の方が細かく管理できそうなので、
今回はCUI操作でのソフトウェアRAIDの管理について
1.RAIDアレイの構築
/dev/sdb、/dev/sdc 2台のHDDを使用してRAID1(ミラー)を構築する
①.partedコマンドでRAIDユニットを作成する
コマンド:parted デバイス
#parted /dev/sdb // sdbを使用する
GNU Parted 3.1
/dev/sdb を使用
GNU Parted へようこそ! コマンド一覧を見るには 'help' と入力してください。
(parted) mklabel gpt // パーティションテーブルをgptに設定(2TB超えのHDD対応)
(parted) mkpart primary xfs 0% 100% // xfsファイルシステムで最大容量のパーティションを作成
(parted) set 1 raid on // RAIDフラグをセット![[ひらめき]](https://blog.ss-blog.jp/_images_e/151.gif)
(parted) p // 状態確認
モデル: ATA VBOX HARDDISK (scsi)
ディスク /dev/sdb: 1074MB
セクタサイズ (論理/物理): 512B/512B
パーティションテーブル: gpt
ディスクフラグ:
番号 開始 終了 サイズ ファイルシステム 名前 フラグ
1 1049kB 1073MB 1072MB primary raid
(parted) quit // 終了
②.同様にsdcも設定する.
③.mdadmコマンドでRAIDアレイをmd0として作成する
// sdb、sdc2台のHDDでRAIDレベル1(ミラー)アレイmd0を作成
#mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sd[bc]
④.後はGUIでの構築同様<アプリケーション>-<ユーティリティ>-「ディスク」を
使用し、RAIDアレイを初期化 → マウントすればストレージとして使用可能![[るんるん]](https://blog.ss-blog.jp/_images_e/146.gif)
2.DAIDの状態確認
コマンド:cat /proc/mdstat
①.RAID構築中の場合
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdc[1] sdb[0]
1047552 blocks super 1.2 [2/2] [UU]
[==>..................] resync = 14.4% (151936/1047552) finish=0.7min speed=18992K/sec
unused devices: <none>
②.RAID状態正常の場合
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdc[1] sdb[0]
1047552 blocks super 1.2 [2/2] [UU] // [UU]の表示が正常の証
③.RAID状態異常(HDDの異常検出)の場合
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb[0](F) sdc[1] // dev/sdbの異常を検出 (F) 表示
1047552 blocks super 1.2 [2/1] [_U] // // [_U] U → _ 表示に変わる
④.RAID状態異常(HDDロスト)の場合
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb[0] // dev/sdcが認識できない
1047552 blocks super 1.2 [2/1] [U_] // [U_] U → _ 表示に変わる
3.RAIDの異常検出からの復旧手順
1.で構築のRAID構成にて /dev/sdb HDDの異常を検出した想定
①.DAIDの状態を確認
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb[0](F) sdc[1] // dev/sdbの異常を検出 (F) 表示
1047552 blocks super 1.2 [2/1] [_U] // // [_U] U → _ 表示に変わる
②.障害発生HDDをRAIDアレイから切り離し
#mdadm --remove /dev/md0 /dev/sdb
mdadm: hot removed /dev/sdb from /dev/md0
③.障害発生HDDを交換する
④.1 - ①の手順でRAIDユニット再作成
⑤.RAIDアレイ再構築
#mdadm --manage /dev/md0 --add /dev/sdb
mdadm: added /dev/sdb
⑥.DAIDの状態を確認
// 再構築中
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb[2] sdc[1]
1047552 blocks super 1.2 [2/1] [_U]
[==>..................] recovery = 12.8% (135552/1047552) finish=0.5min speed=27110K/sec
↓↓↓
// 再構築完了
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdc[1] sdb[0]
1047552 blocks super 1.2 [2/2] [UU]
4.その他
RAIDアレイを削除する
#mdadm --misc --stop /dev/md0
以上、CUI操作でのソフトウェアRAIDの管理についてでした。
状態の確認や再構築の方法等を考えるとCUI操作の方が細かく管理できそうなので、
今回はCUI操作でのソフトウェアRAIDの管理について
1.RAIDアレイの構築
/dev/sdb、/dev/sdc 2台のHDDを使用してRAID1(ミラー)を構築する
①.partedコマンドでRAIDユニットを作成する
コマンド:parted デバイス
#parted /dev/sdb // sdbを使用する
GNU Parted 3.1
/dev/sdb を使用
GNU Parted へようこそ! コマンド一覧を見るには 'help' と入力してください。
(parted) mklabel gpt // パーティションテーブルをgptに設定(2TB超えのHDD対応)
(parted) mkpart primary xfs 0% 100% // xfsファイルシステムで最大容量のパーティションを作成
(parted) set 1 raid on // RAIDフラグをセット
(parted) p // 状態確認
モデル: ATA VBOX HARDDISK (scsi)
ディスク /dev/sdb: 1074MB
セクタサイズ (論理/物理): 512B/512B
パーティションテーブル: gpt
ディスクフラグ:
番号 開始 終了 サイズ ファイルシステム 名前 フラグ
1 1049kB 1073MB 1072MB primary raid
(parted) quit // 終了
②.同様にsdcも設定する.
③.mdadmコマンドでRAIDアレイをmd0として作成する
// sdb、sdc2台のHDDでRAIDレベル1(ミラー)アレイmd0を作成
#mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sd[bc]
④.後はGUIでの構築同様<アプリケーション>-<ユーティリティ>-「ディスク」を
使用し、RAIDアレイを初期化 → マウントすればストレージとして使用可能
2.DAIDの状態確認
コマンド:cat /proc/mdstat
①.RAID構築中の場合
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdc[1] sdb[0]
1047552 blocks super 1.2 [2/2] [UU]
[==>..................] resync = 14.4% (151936/1047552) finish=0.7min speed=18992K/sec
unused devices: <none>
②.RAID状態正常の場合
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdc[1] sdb[0]
1047552 blocks super 1.2 [2/2] [UU] // [UU]の表示が正常の証
③.RAID状態異常(HDDの異常検出)の場合
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb[0](F) sdc[1] // dev/sdbの異常を検出 (F) 表示
1047552 blocks super 1.2 [2/1] [_U] // // [_U] U → _ 表示に変わる
④.RAID状態異常(HDDロスト)の場合
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb[0] // dev/sdcが認識できない
1047552 blocks super 1.2 [2/1] [U_] // [U_] U → _ 表示に変わる
3.RAIDの異常検出からの復旧手順
1.で構築のRAID構成にて /dev/sdb HDDの異常を検出した想定
①.DAIDの状態を確認
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb[0](F) sdc[1] // dev/sdbの異常を検出 (F) 表示
1047552 blocks super 1.2 [2/1] [_U] // // [_U] U → _ 表示に変わる
②.障害発生HDDをRAIDアレイから切り離し
#mdadm --remove /dev/md0 /dev/sdb
mdadm: hot removed /dev/sdb from /dev/md0
③.障害発生HDDを交換する
④.1 - ①の手順でRAIDユニット再作成
⑤.RAIDアレイ再構築
#mdadm --manage /dev/md0 --add /dev/sdb
mdadm: added /dev/sdb
⑥.DAIDの状態を確認
// 再構築中
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb[2] sdc[1]
1047552 blocks super 1.2 [2/1] [_U]
[==>..................] recovery = 12.8% (135552/1047552) finish=0.5min speed=27110K/sec
↓↓↓
// 再構築完了
#cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdc[1] sdb[0]
1047552 blocks super 1.2 [2/2] [UU]
4.その他
RAIDアレイを削除する
#mdadm --misc --stop /dev/md0
以上、CUI操作でのソフトウェアRAIDの管理についてでした。
CentOS7クライアントをADドメインに参加させる [Linux]
今回はCentOS7クライアントをADドメインに参加させます
まず、ドメインコントローラーにアクセスできる事を確認します。
realm discover ドメイン名
# realm discover test-ad.local
Test-AD.local
type: kerberos
realm-name: TEST-AD.LOCAL
domain-name: test-ad.local
configured: kerberos-member
server-software: active-directory
client-software: winbind
required-package: oddjob-mkhomedir
required-package: oddjob
required-package: samba-winbind-clients
required-package: samba-winbind
required-package: samba-common-tools
login-formats: %U
login-policy: allow-any-login
test-ad.local
type: kerberos
realm-name: TEST-AD.LOCAL
domain-name: test-ad.local
configured: no
続いてドメインに参加します。
realm join ドメイン名
# realm join test-ad.local
Administrator に対するパスワード: ← パスワードを入力します
エラーが出なければ、これでドメインに参加できた筈です。
簡単![[exclamation&question]](https://blog.ss-blog.jp/_images_e/159.gif)
では、ドメインユーザーを追加してみます。
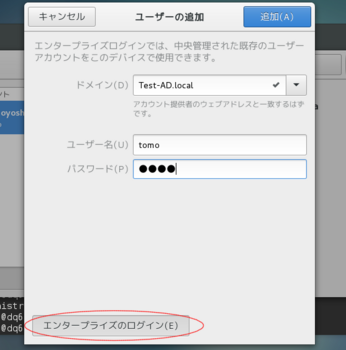
ユーザーの追加画面で「エンタープライズのログイン」をクリックし、
ドメインを参照し、ユーザー情報を入力します。
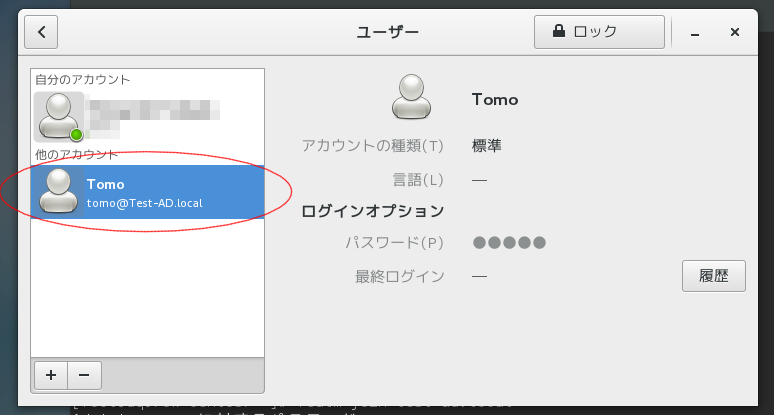
↓ハイ、ドメインユーザーが追加できました
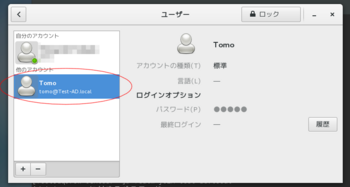
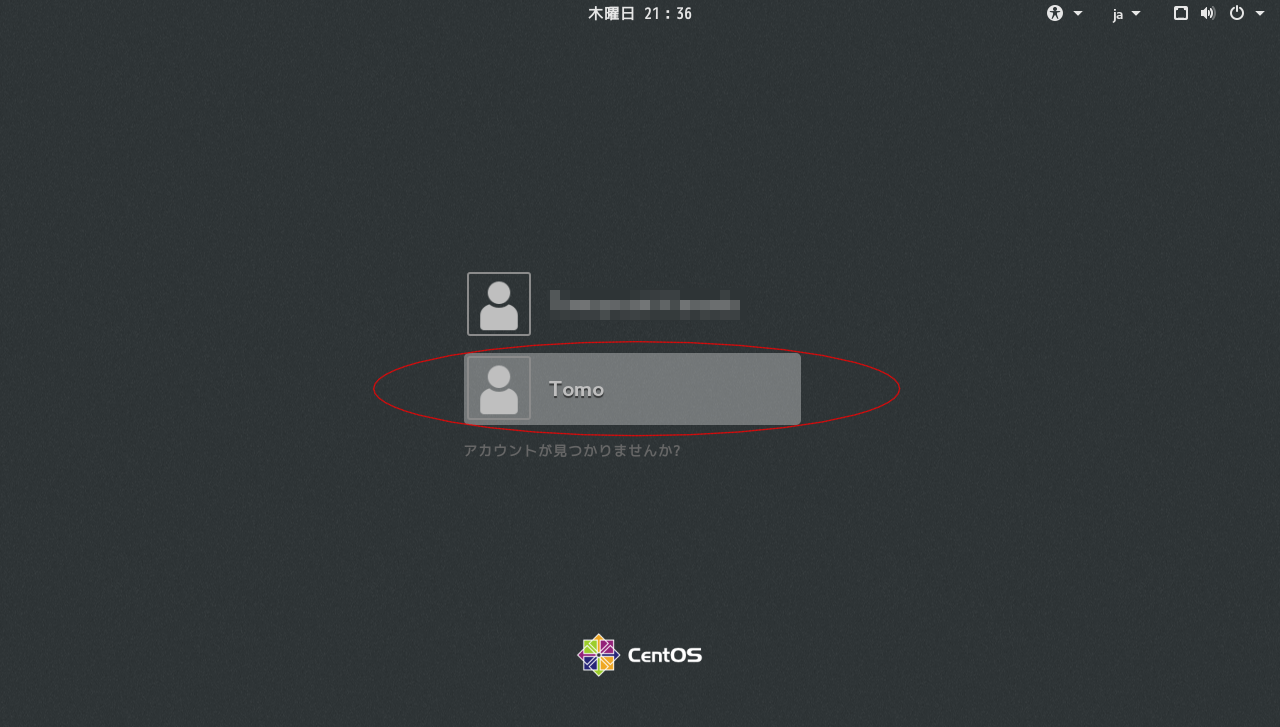
一度ログアウトして、ドメインユーザーでログインします。
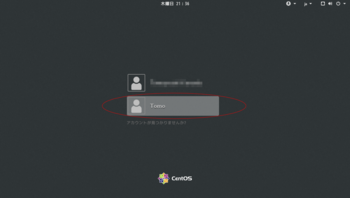
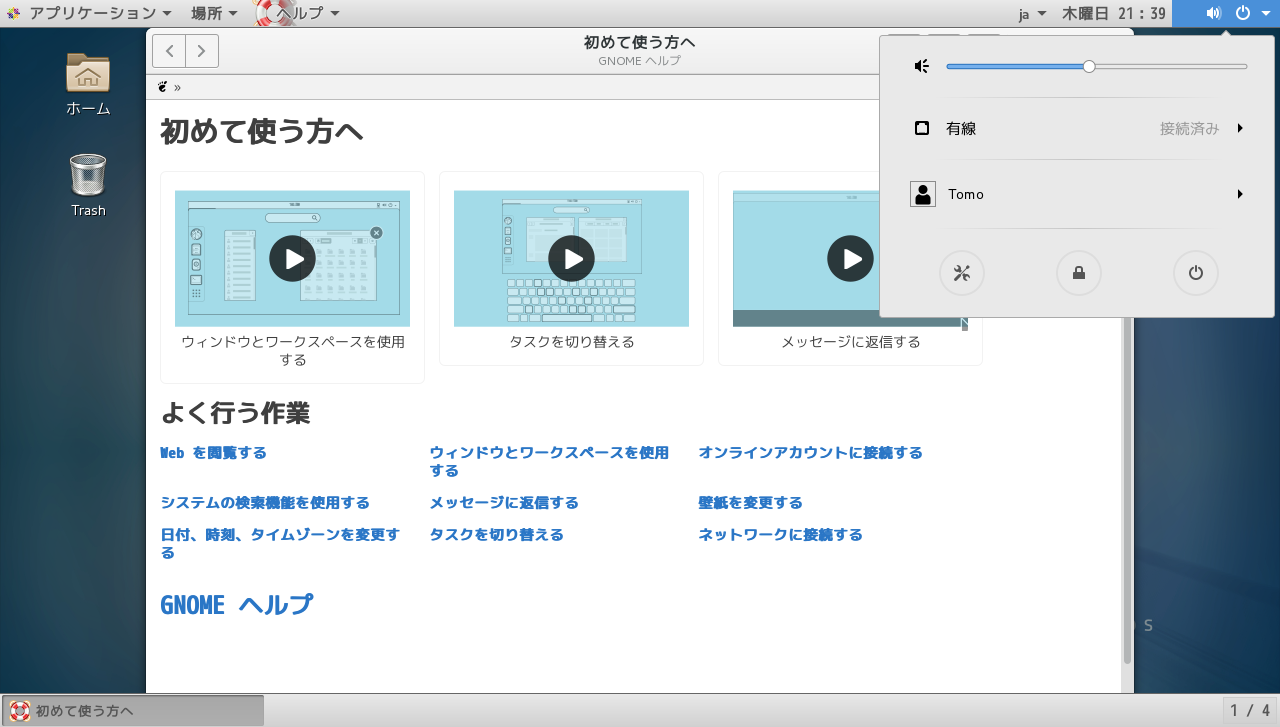
これで、WindowsもLinuxも合わせてユーザーの一括管理が可能になりました![[グッド(上向き矢印)]](https://blog.ss-blog.jp/_images_e/145.gif)
以上、「CentOS7クライアントをADドメインに参加させる」でした。
まず、ドメインコントローラーにアクセスできる事を確認します。
realm discover ドメイン名
# realm discover test-ad.local
Test-AD.local
type: kerberos
realm-name: TEST-AD.LOCAL
domain-name: test-ad.local
configured: kerberos-member
server-software: active-directory
client-software: winbind
required-package: oddjob-mkhomedir
required-package: oddjob
required-package: samba-winbind-clients
required-package: samba-winbind
required-package: samba-common-tools
login-formats: %U
login-policy: allow-any-login
test-ad.local
type: kerberos
realm-name: TEST-AD.LOCAL
domain-name: test-ad.local
configured: no
続いてドメインに参加します。
realm join ドメイン名
# realm join test-ad.local
Administrator に対するパスワード: ← パスワードを入力します
エラーが出なければ、これでドメインに参加できた筈です。
簡単
では、ドメインユーザーを追加してみます。
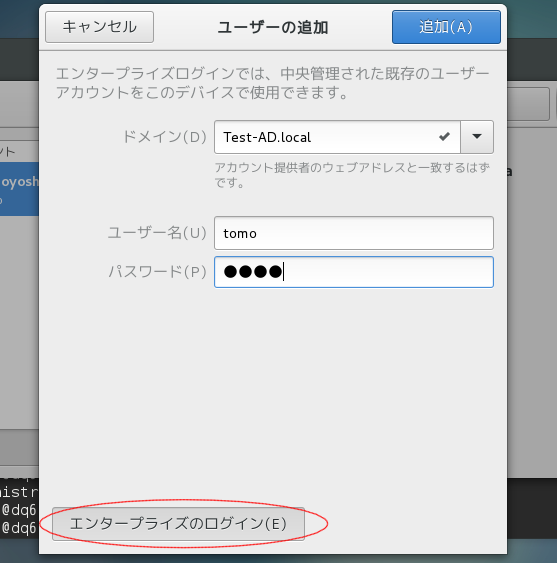
ユーザーの追加画面で「エンタープライズのログイン」をクリックし、
ドメインを参照し、ユーザー情報を入力します。
↓ハイ、ドメインユーザーが追加できました
一度ログアウトして、ドメインユーザーでログインします。
これで、WindowsもLinuxも合わせてユーザーの一括管理が可能になりました
以上、「CentOS7クライアントをADドメインに参加させる」でした。
Tomo さん

-
nice! 12
記事 50
テーマ パソコン・インターネット
プロフィール
ブログを紹介する


